
AI Competitor Benchmarking: From SERP to Strategy Memo Without a Senior Analyst
AI competitor benchmarking works when it turns pricing pages, reviews, positioning, and traction signals into a cited comparison grid a founder or strategist can challenge before Monday.
Friday, 3:42 PM. Someone drops a simple question into Slack: Where do we stand against Superhuman, Shortwave, and Lindy on pricing, positioning, and actual workflow depth? The senior analyst is out. The deck is due Monday. You have a SERP, a coffee, and about six tabs too many.
That is the real use case for an ai competitor benchmarking workflow. Not a giant market map. Not a vague summary. A decision artifact: one comparison grid, built from public evidence, with enough tension left in the report that a founder, consultant, or PM can still challenge it before acting.
Quick verdict: The best competitor benchmarking tool does not write a smoother summary. It assembles a cited grid across pricing, positioning, customer proof, and delivery mechanics fast enough to help on Friday, while keeping the contradictions visible enough to prevent a bad Monday decision.
This is a modeled workflow for a four-competitor benchmark that pulled pricing pages, review surfaces, and positioning pages into one memo-ready grid. The point is the tempo difference, not fake precision.
The reason this workflow matters now is trust. G2's 2024 buyer behavior research found that 31% of buyers lean most on public review sites when researching purchases, while vendor-controlled narratives keep losing credibility. 6sense's buyer-experience research says most eventual winners are already on the shortlist before the vendor ever shows up in a live sales conversation. That means a benchmark built from homepage copy alone is not just incomplete. It is strategically late. G2 6sense
What competitor benchmarking used to mean
Traditional competitor benchmarking often meant a six-week consulting rhythm: collect screenshots, dump them into slides, normalize a few metrics, then bury the actual finding somewhere around slide 47. The deliverable looked expensive because it was long.
What most teams actually need is narrower and sharper:
- What does each competitor claim?
- What do they charge to make that claim believable?
- What do customers or the product surface suggest they are really good at?
- Where is the contradiction?
- What should we do because of that contradiction?
That is benchmarking. The memo is the wrapper. The grid is the work.
If you need the broader discipline behind this workflow, start with Competitive Intelligence Without the Spyware Budget. If you need the category-level version before naming direct rivals, read AI Market Research Tool.
The workflow, concrete
For a concrete example, use a category small enough to inspect fast and rich enough to matter: AI email assistants. It is a good benchmark category because the products look similar from 30 feet, but diverge quickly once you compare pricing, voice adaptation, inbox depth, and automation scope.

A usable ai competitor benchmarking flow looks like this:
- Product researcher pulls pricing pages, feature pages, and docs.
- Community researcher checks review surfaces, forums, and recurring buyer language.
- Traction researcher looks for team size, funding, integration breadth, and enterprise signals.
- Contrarian pass asks what the first three researchers might be overstating.
- Report writer compresses that evidence into one grid plus one recommendation memo.
The important part is not that the work is parallel. It is that the output stays auditable. You should be able to point to the exact page that justified each important cell in the comparison.
The actual comparison grid
Below is the artifact most teams actually want. Not prose first. A benchmark grid first.
| Tool | Starting price | What the product is really selling | Strongest signal | Obvious tradeoff |
|---|---|---|---|---|
| Inbox Ninja | $19/mo Basic, $39/mo Plus (inboxninja.ai/pricing) | Voice-matched drafting and inbox triage for people who want replies to sound like them | Clear position on voice learning and lower entry price than premium inbox tools | Less status prestige than Superhuman; narrower public proof surface today |
| Superhuman | $25/user Starter, $33/user Business pricing | Premium speed and inbox ergonomics for high-volume teams | Strong AI layer plus clear team collaboration and admin controls on the pricing surface | Price climbs fast if your main need is better drafts rather than full inbox workflow depth |
| Shortwave | $24/user Business, $36/user Premier, $100/user Max pricing | AI-heavy inbox search, filtering, and organization for users who live in email all day | Best-articulated AI inbox operations layer in the category: AI search, filters, summaries, and personalized writing | Feature surface is broad enough to feel heavier than a simple writing assistant |
| Lindy | $49.99/mo Plus, $99.99/mo Pro, $199.99/mo Max pricing | An AI operator that happens to include email, meetings, and browser actions | Broader automation scope than the email-first tools, especially for scheduling and cross-app workflows | If the buyer just wants a better inbox, Lindy can be more system than they need |
That grid is intentionally blunt. It lets you compare the category on the dimensions a strategist actually uses in a memo:
- Product capability — what the workflow can do beyond generic drafting
- Pricing — where the product anchors its value
- Positioning — what promise shows up most clearly on the surface
- Distribution signal — who the product seems built for
- Traction proxy — how mature the team, admin, or automation story looks publicly
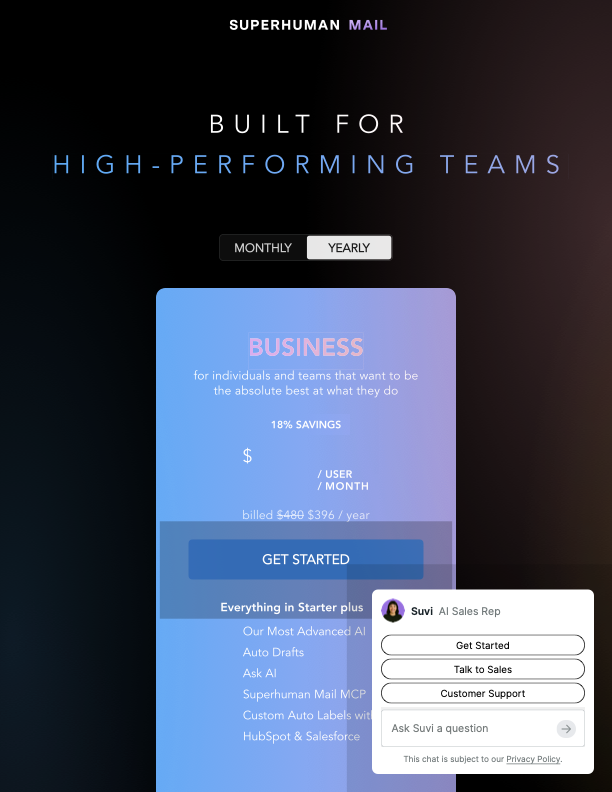

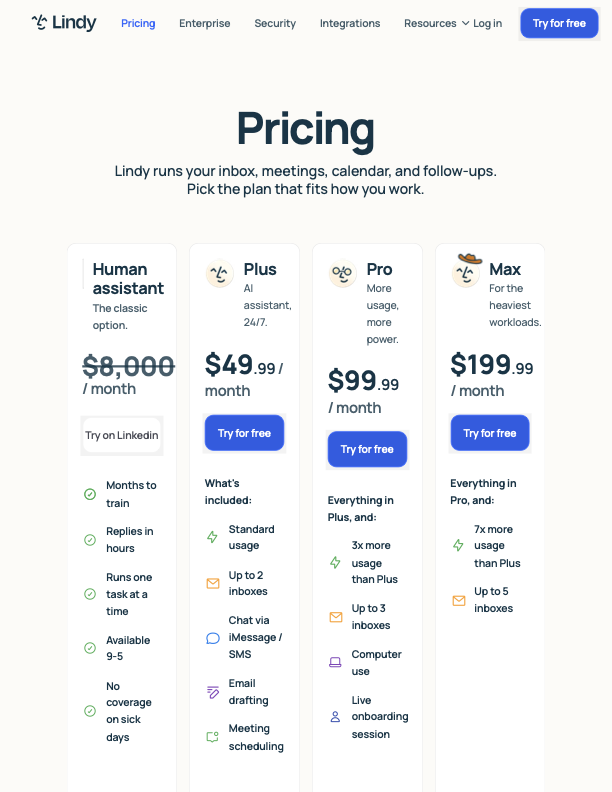
Those three surfaces are why screenshot evidence matters. Before you read a review or a founder interview, the pricing page already tells you where each product thinks its moat lives.
If you want the more general version of this evaluation logic, AI Competitor Analysis covers the evidence discipline behind it.
The 5 dimensions of a real benchmark grid
A benchmark becomes useful when every row answers the same five questions.
1. Product capability
Not feature count. Decision-relevant capability. For an email category, that means things like voice adaptation, AI search, thread handling, scheduling, and admin controls.
2. Pricing
What is the cheapest believable entry point, and what story does that price tell? Superhuman signals premium workflow speed. Shortwave signals power-user depth. Lindy signals broader operator scope. Inbox Ninja signals that voice-matched drafting should not require a $30+ starting point.
3. Positioning
You are not benchmarking adjectives. You are benchmarking the buyer each company is trying to own.

That sentence is worth more than a dozen generic product adjectives. It tells you the product is not really selling drafting. It is selling identity: speed, standards, and the feeling of staying ahead. Once you see that, the rest of the benchmark reads differently.
4. Distribution
Where do you see the go-to-market focus: solo professionals, executives, teams, or enterprise admins? Pricing pages, plan structure, and support language usually answer this faster than the homepage.
5. Traction and proof
This is where the memo becomes useful. Does the product have credible enterprise controls? Distinct workflow depth? Review gravity? Public trust markers? Without this layer, you are comparing taglines.
Benchmarking gets better as soon as you compare comparable surfaces instead of asking one model for a tidy category opinion.
What to give the human
The human does not need every tab you opened. They need:
- One benchmark grid they can scan in two minutes
- One contrarian note on what the grid might still be missing
- One recommendation memo that says where to attack, where to ignore, and where to gather more proof
That final contrarian pass matters because competitor benchmarking fails when the report becomes too neat. If every rival fits a perfect archetype, you are probably reading marketing categories back to yourself. The useful memo preserves at least one uncomfortable tension.
For example, this email-assistant benchmark leaves a clean strategic read:
Memo-ready take: Superhuman looks strongest when the buyer wants status, speed, and team workflow polish. Shortwave looks strongest when the buyer wants AI operating inside the inbox itself. Lindy looks strongest when the buyer wants a broader work operator, not just email. Inbox Ninja's opening is clear: voice-faithful drafting and triage at a lower starting price than the prestige inbox tools.
That is the output a founder can act on.
FAQ: competitor benchmarking tool
What is a competitor benchmarking tool?
A competitor benchmarking tool compares direct rivals on the same decision dimensions: pricing, positioning, workflow depth, proof, and obvious tradeoffs. The useful version returns a grid or memo you can challenge, not just a summary paragraph.
What is the difference between competitor benchmarking and competitor analysis?
Competitor analysis is broader. It can include market structure, messaging, product reviews, channel strategy, and customer complaints. Competitor benchmarking is the compression layer inside that work: the side-by-side artifact that helps a team decide.
What makes AI competitor benchmarking credible?
Three things: public evidence, comparable dimensions, and visible contradictions. If the output cannot show where it got the claim, the benchmark is just opinion with nicer formatting.
Sources
- G2 2024 Buyer Behavior Report — used for buyer-trust framing around reviews and vendor skepticism.
- 6sense B2B Buyer Experience Report — used for shortlist and buying-process framing.
- Superhuman pricing — used for current plan structure and starting-price comparison.
- Shortwave pricing — used for current plan structure and AI workflow comparison.
- Lindy pricing — used for current plan structure and broader automation positioning.
- Superhuman about — used for Rahul Vohra attribution and positioning language on the public company surface.
- Inbox Ninja pricing — used for cross-product price comparison.
Why Rabbit Hole fits this job
Rabbit Hole works as a competitor benchmarking tool because it treats the deliverable as a multi-source evidence problem. Pricing pages, docs, review surfaces, and public signals can be searched in parallel, then compressed into one report that still carries confidence and contradiction.
That is the difference between a Friday summary and a Monday strategy memo.
If that is the standard, try Rabbit Hole. It is built for teams that need research they can actually defend.
Related Articles

The 2026 Buyer's Guide to AI-Powered Research Assistants
The best ai-powered research assistant in 2026 depends on whether you need a fast answer, a literature workflow, or a report you can actually defend after the meeting.

ChatGPT Deep Research vs Perplexity vs Rabbit Hole: Which One Cites Sources That Actually Exist?
If a deep research tool gives you a polished paragraph with one dead link or one unsupported claim, the report is already compromised. Here is the citation test that matters.

AI Patent Search: From IPC Code to Cited Report in 5 Minutes
Patent search is not one query. It is text, classification, citations, and non-patent literature across multiple databases. Here is the workflow that gets you from an IPC code to a cited report faster without pretending verification is optional.
Ready to try honest research?
Rabbit Hole shows you different perspectives, not false synthesis. See confidence ratings for every finding.