
The 2026 Buyer's Guide to AI-Powered Research Assistants
The best ai-powered research assistant in 2026 depends on whether you need a fast answer, a literature workflow, or a report you can actually defend after the meeting.
If you are looking for an ai-powered research assistant in 2026, you are not really shopping for a chatbot. You are choosing a failure mode.
Do you want the failure mode of a fast answer that misses nuance? A polished report that hides weak evidence? Or a slower system that makes contradictions visible before you act on them?
That is the real category split.
Short answer: ChatGPT Deep Research is strong for first-pass synthesis. Perplexity is strong for fast retrieval. Elicit, Consensus, and Scite are strongest when the job is paper-led. Rabbit Hole is strongest when the deliverable has to survive scrutiny after the meeting.
Fast path: Jump to the 2-minute verdict · Jump to the four buying criteria · Jump to the pricing snapshot · Jump to the final pick
If you only have 2 minutes
| If your situation is... | Best fit | Why |
|---|---|---|
| You need a quick market scan or broad first pass | Perplexity | Fast web retrieval with a clean citation layer |
| You need a readable brief fast and will verify it yourself | ChatGPT Deep Research | Strong narrative synthesis, weaker source discipline |
| You need a literature workflow built around papers | Elicit / Consensus / Scite | Better paper-led structure, extraction, and citation context |
| You need something you can defend in a partner meeting, client memo, or diligence review | Rabbit Hole | Stronger source separation, contradiction handling, and reusable deliverables |
Do not pick on fluency alone. Pick on the cost of being wrong in the context you actually work in.
The buyer's framing: you are picking a source discipline, not just a model
Most reviews of AI research tools compare them like note-taking apps. That misses the point.
A real research workflow has four jobs:
- Find the right evidence across the open web, papers, filings, forums, docs, and product surfaces.
- Weight that evidence correctly instead of flattening a peer-reviewed paper and a vendor landing page into the same thing.
- Surface disagreement when the sources conflict.
- Ship an artifact you can actually use: a report, memo, table, bibliography, or diligence brief.
That is why the phrase ai-powered research assistant now hides three different product categories:
| Category | Best tools | What you actually get | Where it breaks |
|---|---|---|---|
| Fast answer engines | Perplexity, Gemini Deep Research, You.com Research | A quick map of the web with citations | Weak source hierarchy, easy to over-trust |
| Synthesis engines | ChatGPT Deep Research, Gemini Deep Research | A readable narrative brief | Fluency can hide uncertainty |
| Research-workflow systems | Rabbit Hole, Elicit, Scite, Consensus | A more explicit evidence workflow, often with paper-level or source-level structure | Usually slower, narrower, or less conversational |
If the deliverable is a casual brief for yourself, the first two categories are often enough. If the deliverable is board-facing, client-facing, investment-facing, legal, scientific, or procurement-facing, they usually are not.
If you want the shorter tool-comparison version of this argument, start with Best AI Research Assistants for 2026. If you want the citation-failure evidence underneath it, read AI Search Has a Citation Problem and Deep Research Tools Look Credible. That's the Problem..
The 8 tools in this buyer's guide
We grouped the field by what each product is actually good at, not by who has the loudest launch video.
| Tool | Best for | Core strength | Main caution |
|---|---|---|---|
| Rabbit Hole | High-stakes research reports | Source separation, confidence framing, reusable deliverables | Not the fastest path to a casual answer |
| ChatGPT Deep Research | Fast first-pass synthesis | Coherent narrative output | Polished prose can hide weak evidence |
| Perplexity Deep Research | Rapid web-first exploration | Speed and broad retrieval | Easy to confuse breadth with verification |
| Gemini Deep Research | Google-heavy knowledge work | Broad consumer integration, decent multi-page summaries | Access and source discipline are uneven |
| Elicit | Literature reviews and evidence extraction | Academic-paper workflows, tables, systematic review structure | Less useful for messy market or product research |
| Consensus | Academic question answering | Fast paper-backed search and paper snapshots | Not built for adversarial commercial diligence |
| Scite | Citation context and evidence checking | Smart citations and citation stance | Narrower scope than general-purpose research assistants |
| You.com Research | General web research | Quick multi-source summaries | Weak differentiation on evidence workflow |
The four dimensions that actually matter
A useful ai-powered research assistant should be judged on four dimensions, not one:
1. Citation integrity
Can you click the source and confirm that it exists, says what the report claims, and belongs to the right kind of source?
2. Source coverage
Does the system pull from the source types the job actually needs: papers, docs, SEC filings, GitHub, forums, news, or community evidence?
3. Output format
Do you get a reusable deliverable, or a wall of prose that still has to be turned into a memo by hand?
4. Time to defensible output
Not time to first token. Time to something you would actually forward.

These four checks catch four different ways a research tool can look finished before it is trustworthy.
The best product depends on which compromise you can live with.
What the public evidence already tells you
This category's credibility problem is no longer hypothetical.
In March 2025, Columbia Journalism Review's Tow Center tested eight generative search tools and found that they collectively answered more than 60 percent of article-identification queries incorrectly. Perplexity answered 37 percent incorrectly. More important than the raw miss rate was the behavior: the systems usually preferred a confident wrong answer over an honest admission that retrieval had failed. CJR / Tow Center, March 2025
Tow Center's earlier OpenAI-specific source-attribution test found that ChatGPT returned incorrect article identifications 134 times out of 200 prompts, while only rarely signaling uncertainty. That is the exact failure mode buyers should fear: not obvious nonsense, but authoritative-looking source claims that ask for too much trust. Tow Center, November 2024
OpenAI's own deep research materials also explicitly warn that deep research can hallucinate facts, make incorrect inferences, and communicate uncertainty poorly. That does not make the product useless. It makes the evaluation criteria obvious. OpenAI deep research announcement

These numbers do not prove one winner. They prove that citation integrity has to be a first-class buying criterion.
If you need the practical workflow for catching those failures, save How to Verify AI Research Output.
The buyer's guide: who each tool is actually for
Rabbit Hole
Rabbit Hole is the strongest fit when the work product needs to survive scrutiny after the meeting. Its advantage is not just more sources. It is making evidence structure visible: confidence framing, source layering, contradictions, and reusable artifacts.
That makes it the better fit for:
- investment memos
- vendor or market diligence
- competitive landscapes
- partner or board briefs
- any report where somebody senior will ask, "wait, where did that claim come from?"
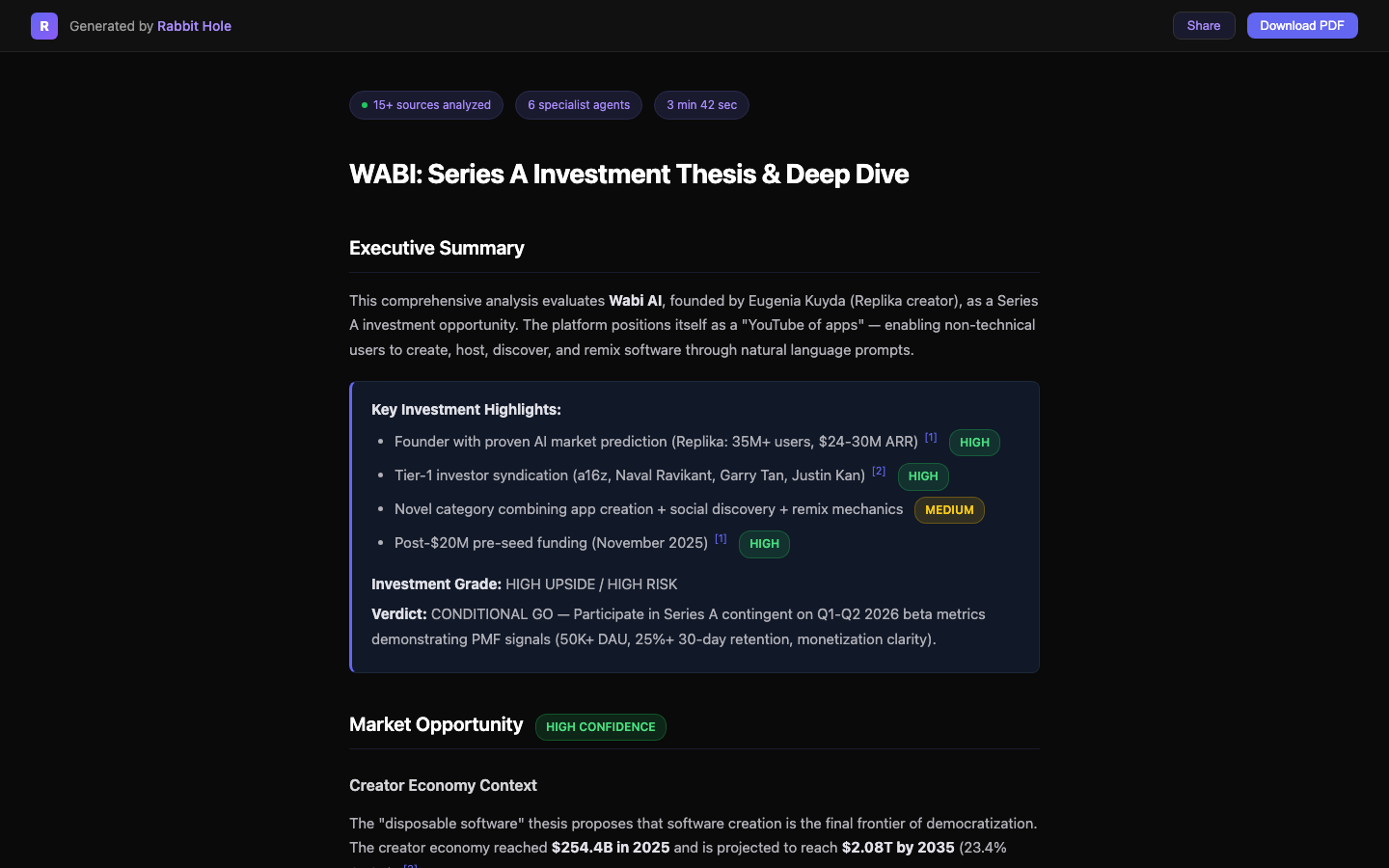
The cost is that it is not built to feel like casual chat. That is the right trade if your real concern is not convenience but defensibility.
ChatGPT Deep Research
ChatGPT Deep Research is the most mainstream proof that users want more than chatbot replies. It is good at holding a broad research goal, browsing for a while, and returning a coherent report.
That makes it excellent for:
- fast market maps
- meeting prep
- internal synthesis drafts
- first-pass briefings before a human review
Its weakness is the same thing that makes it compelling: the output is smooth enough to feel complete before it is actually verified. If you need the deeper tool-by-tool breakdown, read ChatGPT Deep Research Review (2026).
Perplexity Deep Research
Perplexity is still the cleanest speed-first research workflow. It is often the fastest path from question to a decent starting map of the web.
That makes it the right choice for:
- early category scans
- fast source discovery
- quick stakeholder answers
- lightweight research that will not be forwarded unchanged
Where it breaks is source weighting. It helps you find. It does not reliably tell you what deserves the most trust. If your workflow is outgrowing that trade, start with Perplexity Alternative: Why Researchers Switch to Multi-Agent Research.
Gemini Deep Research
Gemini Deep Research sits between consumer convenience and broader Google workflow integration. If you already live in Gmail, Docs, and Search, the product can feel ambient in a way the others do not.
That makes it attractive for:
- generalist knowledge workers already paying for Google AI plans
- teams that want research adjacent to existing Google workflows
- broad exploratory work where integration matters as much as the research itself
The caution is that integration can blur evaluation. Convenience is not the same thing as evidence discipline.
Elicit
Elicit is the clearest signal that academic research is a distinct workflow, not just a flavor of web search. It shines when the job is paper finding, extraction, comparison tables, or systematic review structure.
That makes it the best fit for:
- literature reviews
- evidence extraction from papers
- methodology comparison
- researchers who care more about paper coverage than web breadth
If your job is commercial research instead of academic review, Elicit can feel too narrow. If your job is academic, that narrowness is a feature.

Jungwon Byun, cofounder and COO of Elicit, as shown on Elicit's public team page. The positioning matches the product: structured research workflow first, general-purpose assistant second.
Pricing snapshot: what you are really paying for
Exact pricing changes often, but the important pattern is already visible.
| Tool | Public entry point | What you are paying for |
|---|---|---|
| Rabbit Hole | Free tier, then Basic $29/mo and Plus $79/mo (pricing) | Fewer reports than chat-first tools, but stronger artifact quality per report |
| ChatGPT | Free, Plus $20/mo, Pro $200/mo (pricing) | Broad utility plus deep-research access inside a general assistant |
| Perplexity | Free tier, Pro around $20/mo (pricing) | Speed, retrieval, and broad everyday search utility |
| Gemini | Free, Google AI Plus $7.99/mo, Pro $19.99/mo, Ultra $249.99/mo (subscriptions) | Integration with Google's wider productivity surface |
| Scite | Personal plan $20/mo annual or $25/mo monthly; power researcher plan $50/mo (pricing) | Citation-context intelligence and deeper research datasets |
| Elicit | Free, Plus $7/mo billed annually, Pro $29/mo billed annually, Scale $49/mo billed annually (pricing) | Paper-first workflow depth; the jump to Pro is really a jump into systematic-review work |
| Consensus | Free, Pro $15/mo monthly or $10/mo billed annually, Deep $65/mo monthly or $45/mo billed annually (pricing) | Cheap entry for paper-backed Q&A, then a sharp jump for heavier literature work |
| You.com | No obvious self-serve research-seat pricing on the public product surface; messaging leans toward workplace AI and API sales (homepage, platform) | A signal that the product is broad AI infrastructure first, specialist research workflow second |
Price matters, but the bigger question is what you get for that spend: fast answers, polished synthesis, or an auditable report with confidence ratings.
The more useful comparison is not the sticker price. It is the cost of a confident wrong answer.
There is also a subtler pricing signal hiding in plain sight. Elicit and Consensus both make the academic workflow explicit in their plan design: more reports, deeper extraction, more paper volume. ChatGPT and Perplexity price research as one feature inside a broader assistant. You.com's public surface, by contrast, reads more like AI infrastructure and workplace search than a buyer's guide for a dedicated research seat. That matters because pricing pages usually reveal the product the company thinks it is selling.
If the output is guiding a client recommendation, investment decision, clinical summary, vendor shortlist, or legal position, the cheapest tool can become the most expensive one very quickly.
You can see that split directly in the public surfaces:
Source: Consensus pricing, captured May 15, 2026. The page is explicit about the step-up from casual paper-backed answers to heavier research volume.
Source: Scite pricing, captured May 15, 2026. The public plan language centers citation intelligence and research depth rather than broad everyday search.
Source: about.you.com, captured May 15, 2026. The buyer story is broader AI infrastructure and workplace agents, which is useful context if you are specifically shopping for a dedicated research seat.
What the public product surfaces reveal before you even run a trial
You can learn a surprising amount from the way each tool presents its work before you hand it a real query.
ChatGPT's deep-research surface is optimized for a polished report view. Perplexity's public materials emphasize a fast report canvas with shareable outputs. Elicit still foregrounds paper search, extraction, and screening.
That does not settle the buying decision. It does tell you what each team thinks the job is.
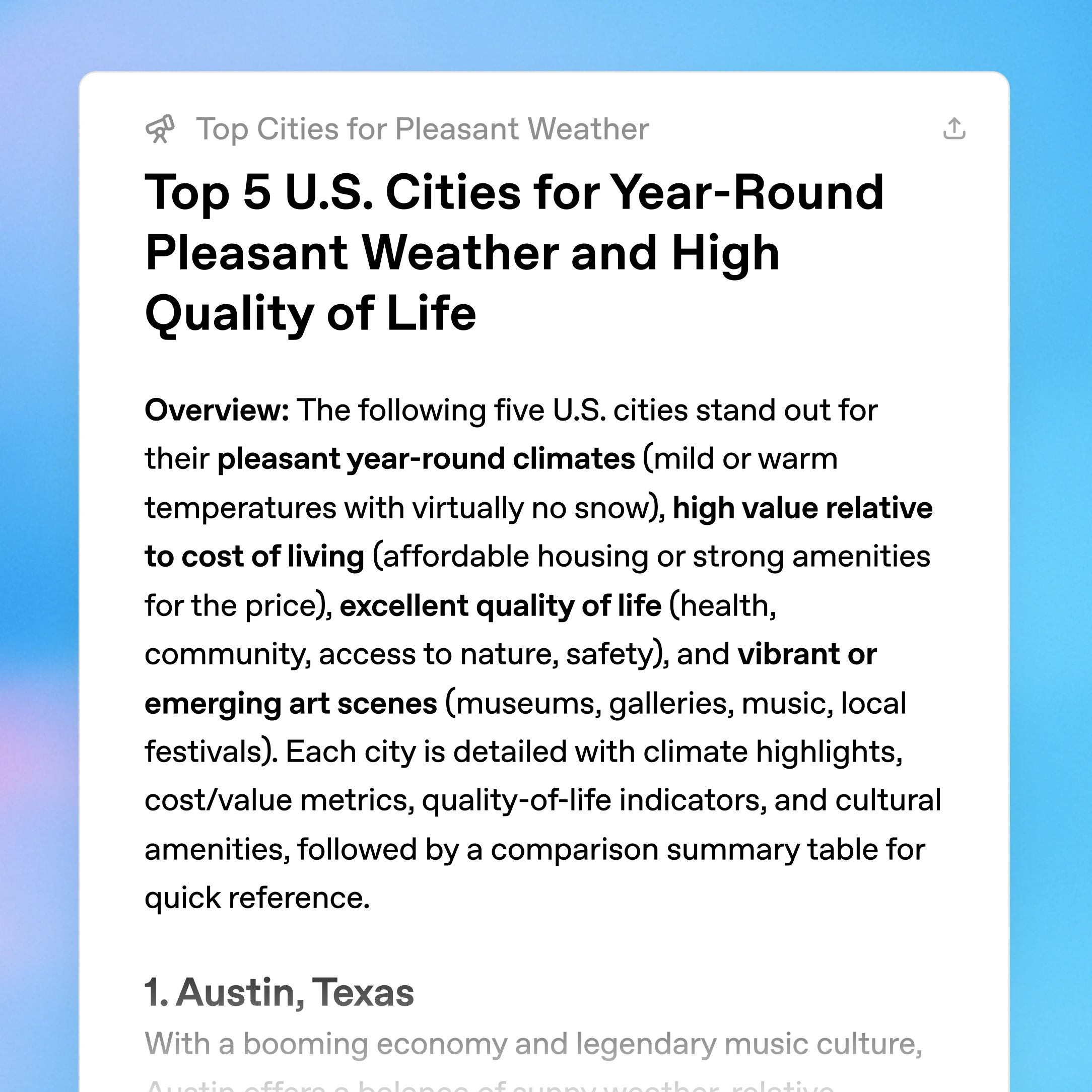
Source: ChatGPT deep research feature page. The presentation is polished and readable, which is great for first-pass synthesis and exactly why buyers still need to verify the underlying source discipline.

Source: Perplexity's deep research announcement. The public surface leans into speed and accessibility: a broad report canvas that feels closer to search than to a diligence workflow.
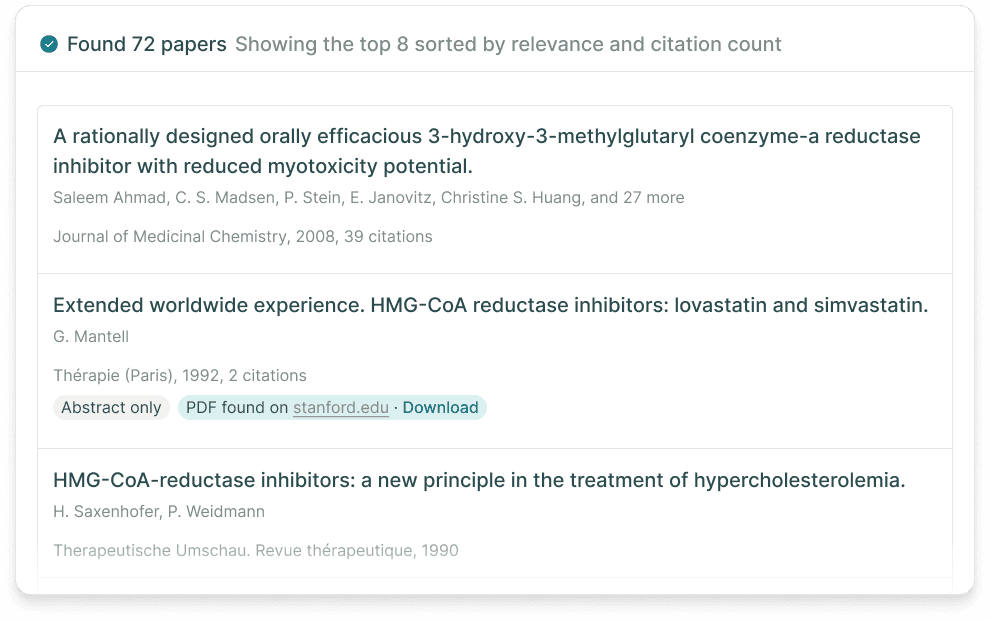
Source: Elicit homepage. Even in the marketing surface, the center of gravity is still papers, rankings, and extraction—not general web synthesis.
A practical scoring matrix
Below is the matrix I would actually use before paying for any of these tools.
| Tool | Citation integrity | Source coverage | Output format | Best fit |
|---|---|---|---|---|
| Rabbit Hole | 5/5 | 5/5 | 5/5 | High-stakes, defensible reports |
| ChatGPT Deep Research | 3/5 | 4/5 | 4/5 | Fast first-pass briefs |
| Perplexity Deep Research | 3/5 | 4/5 | 3/5 | Speed-first exploration |
| Gemini Deep Research | 3/5 | 4/5 | 4/5 | Google-native knowledge work |
| Elicit | 5/5 for papers, 2/5 beyond them | 3/5 | 4/5 | Literature reviews |
| Consensus | 4/5 for papers | 3/5 | 3/5 | Academic Q&A |
| Scite | 5/5 for citation context | 2/5 | 3/5 | Citation checking |
| You.com Research | 2/5 | 3/5 | 3/5 | General web research |
For any research tool, this is still the cheapest trust test: does the source exist, does it say that, who else agrees, is the context right, and what is still missing?
So what is the best ai-powered research assistant in 2026?
There is no universal winner. There is a clean split.
- Pick Perplexity if the downside of being slightly wrong is low and speed matters most.
- Pick ChatGPT Deep Research if you need a readable first-pass brief fast.
- Pick Gemini Deep Research if your workflow is already deeply tied to Google.
- Pick Elicit, Consensus, or Scite if the core job is paper-led rather than market-led.
- Pick Rabbit Hole if the answer needs to survive scrutiny, not just feel finished.
That is the test buyers should adopt from now on.
Do not ask which tool sounds smartest.
Ask which tool makes it easiest to catch itself when it might be wrong.
If you want the shorter comparison between the mainstream options, read Best AI Research Assistants for 2026. If you want the operational version of this article, read AI Due Diligence and How to Verify AI Research Output.
Rabbit Hole is a research assistant for high-stakes work. It separates source types, surfaces uncertainty, and ships reusable reports instead of a wall of chat text.
Related Articles

ChatGPT Deep Research vs Perplexity vs Rabbit Hole: Which One Cites Sources That Actually Exist?
If a deep research tool gives you a polished paragraph with one dead link or one unsupported claim, the report is already compromised. Here is the citation test that matters.

AI Patent Search: From IPC Code to Cited Report in 5 Minutes
Patent search is not one query. It is text, classification, citations, and non-patent literature across multiple databases. Here is the workflow that gets you from an IPC code to a cited report faster without pretending verification is optional.

Zotero + AI: Building a Research Workflow That Actually Cites
Zotero already solves storage and citations. The missing layer is faster discovery with verification before weak sources make it into your library.
Ready to try honest research?
Rabbit Hole shows you different perspectives, not false synthesis. See confidence ratings for every finding.